<프로세스>
1. 장르 피처 벡터화: 문자열로 변환된 genres 칼럼을 Count 기반으로 피처 벡터화 변환
2. 코사인 유사도 계산 : genres 문자열을 피처 벡터화한 행렬로 변환한 데이터 세트를
코사인 유사도로 비교
3. 평점으로 계산 : 장르 유사도가 높은 영화 중 평점이 높은 순으로 영화 추천
from sklearn.feature_extraction.text import CountVectorizer
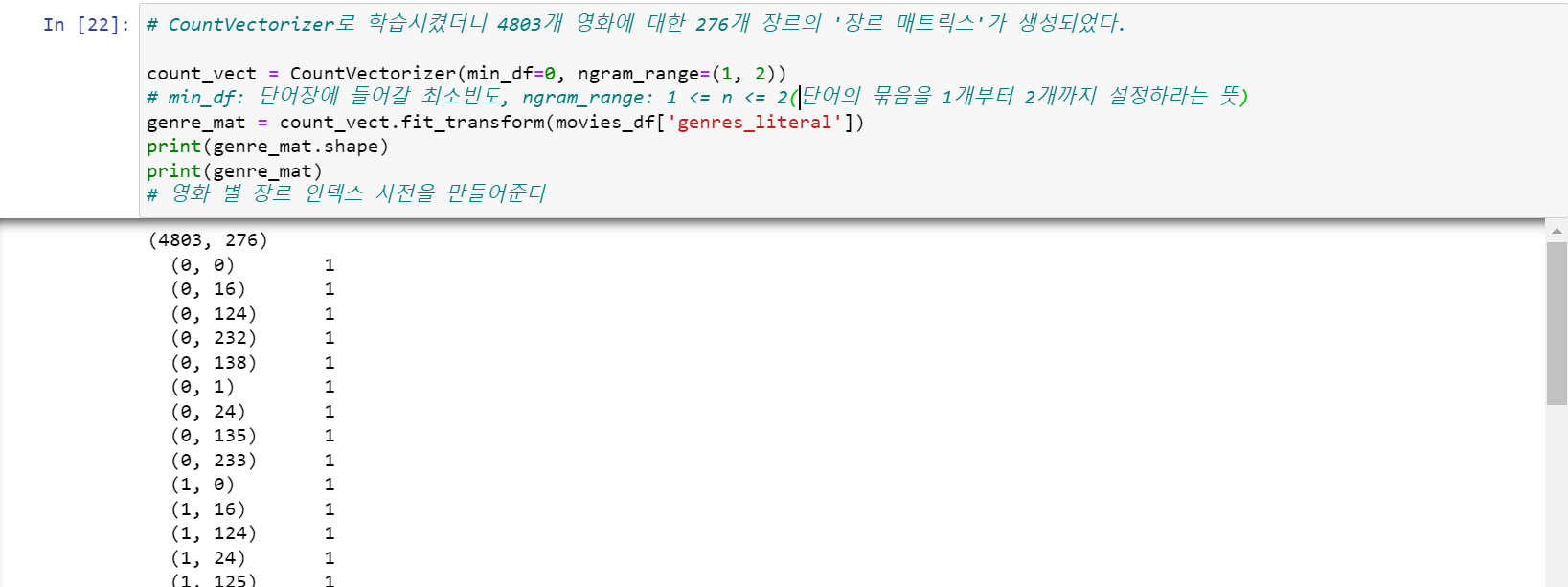
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
▶코사인 유사도에 의해 4803개 영화 각각 유사한 영화들이 계산됨
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)

genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
genre_sim_sorted_ind
'PYTHON > machine_learning' 카테고리의 다른 글
| 경사하강법을 이용한 행렬 분해 (0) | 2022.02.09 |
|---|---|
| 행렬 전치 (0) | 2022.02.08 |
| 가중평균 (0) | 2022.02.08 |
| argsort (0) | 2022.02.08 |
| literal_eval (0) | 2022.02.08 |